如果你這幾天打開 ChatGPT,可能已經發現預設模型變成 GPT-5.5 Instant 了。根據 OpenAI 的說法這次的模型幻覺少了 52.5%。但這個數字到底代表什麼,對我們一般用戶有沒有差,以下我們就來一探究竟。
52.5% 是在哪種情況下測出來的
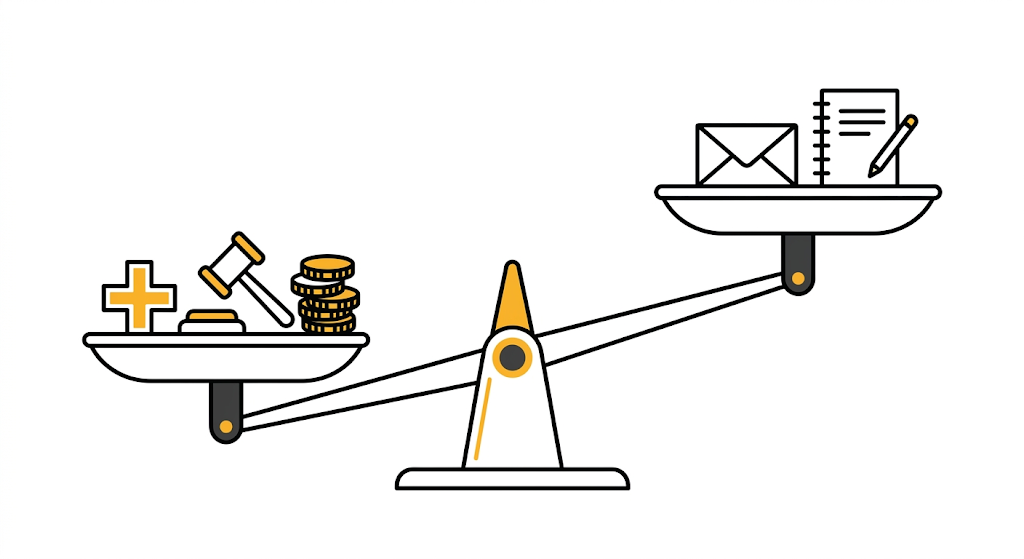
這個數字來自 OpenAI 自己的內部評測,測試的是「高風險提示」,也就是醫療、法律、財務這三類問題。當你問 ChatGPT「這個藥和什麼藥不能一起吃」或「這份合約的這條條款合法嗎」,舊版的模型很容易給出聽起來有理、但其實不準確的答案,而且語氣充滿自信。
另一個數字是 37.3%,測的是「用戶曾標記為事實錯誤的困難對話」,這更接近真實使用的情況。
簡而言之,新模型確實比較不容易犯這類錯,大大減少了一本正經講幹話的機率。
你的日常問題裡,哪些最容易被幻覺坑
幻覺是 AI 語言模型的結構性問題:模型根據「聽起來合理」的模式生成文字,即使它實際上不知道答案。
有幾類問題特別容易踩到這個坑:
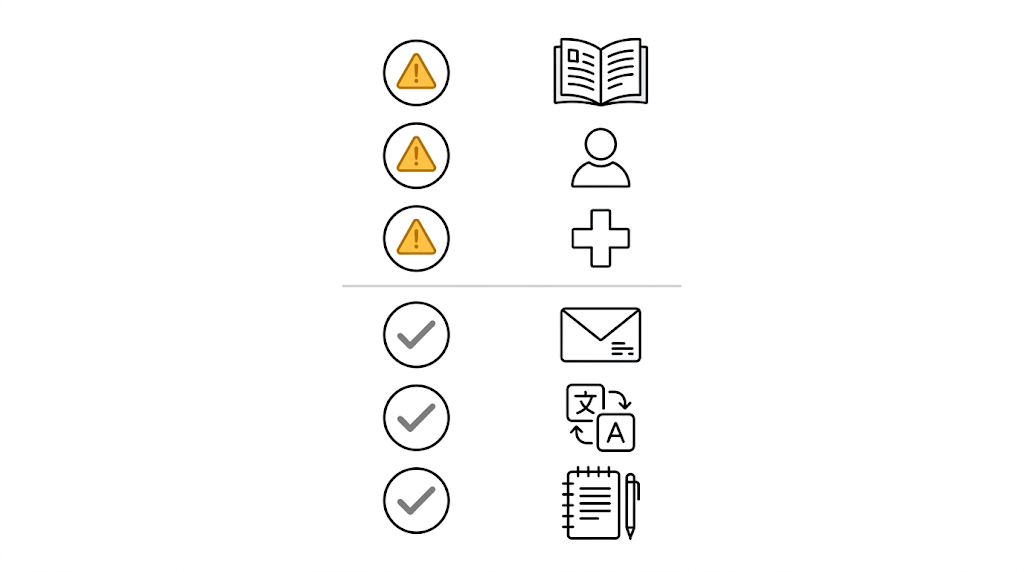
叫它提供來源或引用:這是風險最高的場景。問 ChatGPT「請推薦幾本關於 X 的書,附上作者和出版年份」,它給的書名可能存在,作者可能是真人,但兩者可能根本沒有關係。學術研究顯示,舊版 ChatGPT 生成的引用裡,有高達 47–55% 是捏造的。新版改善了,但你仍然需要自己去確認。
問具體的人名、事蹟、言論:某個人說了什麼話,某件事發生在哪一年,某位名人的經歷,這類問題的幻覺風險比問「怎麼寫信」高很多。
醫療和法律資訊:這是 OpenAI 這次改善最用力的地方,也是過去最危險的場景。
相比之下,你用 ChatGPT 寫信、改履歷、整理筆記、翻譯文字,幻覺幾乎不是問題。這類任務的內容是你自己提供的,模型只需要處理你給的資料,不需要從訓練記憶裡搜索事實。
這次更新一般人真正注意到的改變
52.5% 是針對高風險場景的數字。對一般用戶來說,GPT-5.5 Instant 最明顯的改變其實在回答風格上。
新模型的回答字數大約少了 30%,行數少了近 29%。問一個簡單的問題,它給你一句或幾句直接的答案,不再附上四段有標題有條列的迷你報告。問它意見,它給意見,不會先說「這是個很好的問題,有幾個角度可以考慮…」然後繞半天。
另一個明顯的差別是幾乎沒有無謂的 emoji 了。過去 ChatGPT 很愛在回答裡灑各種表情符號,很多人覺得像是在跟一個過度熱情的客服聊天。新版本的語氣更平,就像在問一個知道答案的朋友,不是在讀一份精心排版的簡報。
「記憶來源」功能也在這次一起上線。ChatGPT 的回答現在可以告訴你它根據的是哪段之前的對話或你上傳的文件,不用猜它為什麼給了這個答案,也可以直接刪掉你不想讓它參考的記憶。
一個還沒解決的問題
52.5% 的改善是真實的,但還剩另外那 47.5%。新模型確實比舊模型謹慎,遇到不確定的事情更願意說「我不確定」,但它仍然有可能很有把握地給出不準確的資訊,尤其是你問的事情不在它訓練資料的核心範圍內。
最有用的應對方式還是一樣:讓它做事,不要直接讓它做你的資料來源。它整理你提供的文字,很準;但回憶它「學過」的具體事實,仍然有一定的風險。





