
如果你打開 ChatGPT 輸入「幫我畫一隻貓」,幾秒鐘後最會產生精美的圖片。切到 Gemini,一樣可以。但同樣的指令在 Claude 上只會得到文字回覆,頂多幫你畫個 SVG 示意圖。
Claude 可以生成 SVG、圖表、HTML 視覺元件,但就是沒辦法像 ChatGPT 或 Gemini 那樣輸出一張像素圖。難道 Anthropic 徹底放棄生圖市場了嗎? 本文帶你一探究竟。
Claude 為什麼沒有跟 GPT 和 Gemini 一樣的生圖能力
首先,要搞清楚這個問題,要先理解一件事:生圖和寫字是兩種完全不同的 AI 架構。
GPT 用的是 GPT Image 2(前身是 DALL·E 3,已於 2026 年 5 月停用),Gemini 用的是 Nano Banana 2(Google 的官方生圖模型品牌,基於 Gemini 3.1 Flash Image),這兩個背後都是擴散模型(diffusion model),一種專門把文字描述轉換成像素圖的架構。跟語言模型不是同一個東西,要從頭訓練,要有獨立的資料集,要有獨立的安全機制。
Claude 是語言優先的模型,它可以生成 SVG 向量圖、圖表、互動式視覺元件,但沒有把文字描述轉換成像素圖的那一段。兩套系統本來就不是同一種東西。
所以 Claude 生不了像素圖,跟「技術差不差」沒有直接關係,比較像是「根本就沒裝這個功能」,而且這個選擇是刻意的。
Anthropic 不是不能,是選擇不做
問題來了:OpenAI 和 Google 都訓練了生圖模型,Anthropic 為什麼選擇不做?
安全問題太難處理
圖像生成的安全問題,比文字複雜很多。Grok 在 2025 年底接入 Flux.1 生圖功能後,因為安全機制不夠嚴密,11 天內就跑出了超過 300 萬張不當圖片,後來被歐盟追責。OpenAI 和 Google 在這塊投入了大量資源做測試和過濾,爭議還是持續出現。
Anthropic 把「可信任 AI」當核心定位,做生圖功能就要同時面對 deepfake、版權爭議、安全漏洞這些問題。對一家靠安全聲譽吃飯的公司來說,這個包袱太重。
資源聚焦在代理型 AI 上
Anthropic 2026 年的重心放在代理型 AI(agent AI)。Claude Code、Agent Teams、Claude Cowork,這些讓 Claude 可以自主執行多步驟任務,比如寫程式、整理資料、操作瀏覽器。
開發者是 Claude 最核心的用戶,開發者日常工作裡很少需要生成插圖,更需要能自主執行任務的助手。有限的資源放在能拉開差距的地方,是合理的選擇。
企業端市場的安全門檻
大公司和政府機構在評估 AI 工具時,「不小心生出 deepfake」是真實的採購顧慮。Claude 不生圖,整個把這個類別的風險排除掉了,讓企業通過合規審查更容易。這是一種刻意的市場定位。
Claude Design 是另類的生圖工具嗎
2026 年 4 月 Anthropic 推出了 Claude Design,有些人看到「視覺輸出」就以為這是生圖功能,其實不是。
Claude Design 讓你用對話生成 prototype、簡報、landing page,背後是 HTML、CSS、JavaScript,輸出的是可互動的設計成品,而不是像素圖。可以匯出成 PPTX、PDF 或獨立 HTML,但生不出一張貓的照片。
對需要做設計稿或網頁雛形的人來說很實用,但如果你想要插圖、海報、產品圖,Claude Design 解決不了。
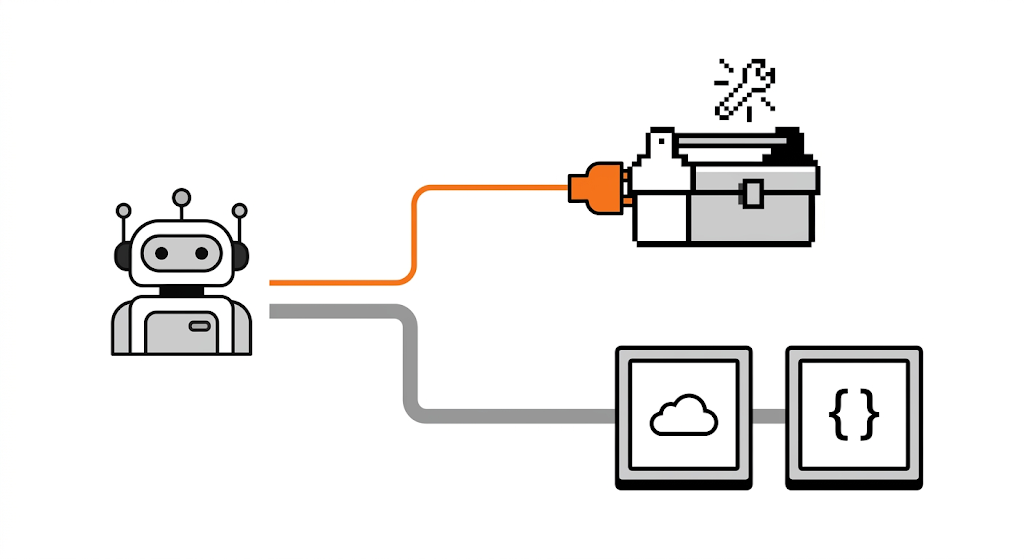
現在想在 Claude 裡生圖,有哪些選項
Anthropic 沒有原生生圖,但可以透過 MCP(Model Context Protocol,讓 Claude 接外部工具的機制)接入第三方生圖服務。目前有人在用的方案是把 Higgsfield AI 接進 Claude,Higgsfield 是一個整合了 Nano Banana Pro、GPT Image 等多個模型的生圖生影片平台,接好後可以直接在對話裡觸發生圖,不用跳到其他平台。但設定上需要一點點技術門檻,不過網路上已經有教學影片可以跟著做。
如果不想折騰設定,更直接的做法是:用 Claude 做文字推理和寫作,圖片需求丟給 ChatGPT 或 Gemini。兩個工具並用,比強迫 Claude 做它沒裝的功能省力得多。





